Nutch爬虫开发
Nutch爬虫开发
介绍
Nutch是一个用Java实现的搜索引擎,它包括全文搜索和网络爬虫。它支持针对不同的业务场景,使用本地运行模式或者基于Hadoop的分布式运行模式。
Nutch目前主要由1.x和2.x两个分支,主要的不同在于数据存储的实现。这里的存储指的是,Nutch本身会保存关于爬取过程中的爬虫的各种状态到称为crawldb的存储中去。1.x是以SequenceFile结构的方式保存到本地或者分布式文件系统中去,而2.x则是把存储层抽象了出来,不再依赖特定的存储结构,而是使用gora来处理存储映射,所以最终可以保存到gora支持的RDBMS、NOSQL(Mongodb、HBase)等各种存储中去。
安装
从这里下载最新的源码包。执行
|
|
会进行依赖包的下载、源码的编译、运行环境的构建等步骤。执行完毕后,
runtime/local目录是独立的本地运行环境conf、build、runtime/deploy目录则是分布式运行环境
NOTE: 对Nutch的配置推荐直接修改conf目录下的配置,因为本地运行环境的构建是由这个目录构建出来的,runtime/local和它的关系相当于build和src的关系。
爬取
网页的爬取可以通过bin目录下的crawl脚本进行自动的爬取,也可以通过nutch脚本进行分部爬虫。为了便于理解Nutch的爬取过程,这里以nutch脚本为例进行爬取。
Nutch的爬取过程分为五个步骤,每个步骤的执行结果都会保存到crawldb中,并通过markers字段记录执行到哪个阶段。
NOTE: 示例中使用Nutch2.3.1版本,并使用Mongodb作为存储。
Inject
从文件中得到一批种子网页,把它们放到抓取数据库中去
|
|
参数
./urls/为要爬去的url的目录- 后面可以跟-crawlId,不加的话默认值为空
crawlId对应crawldb中的表名,规则为${crawlId}_webpage。也就是说不加-crawlId参数的情况下,数据会进入webpage表中。
执行结果
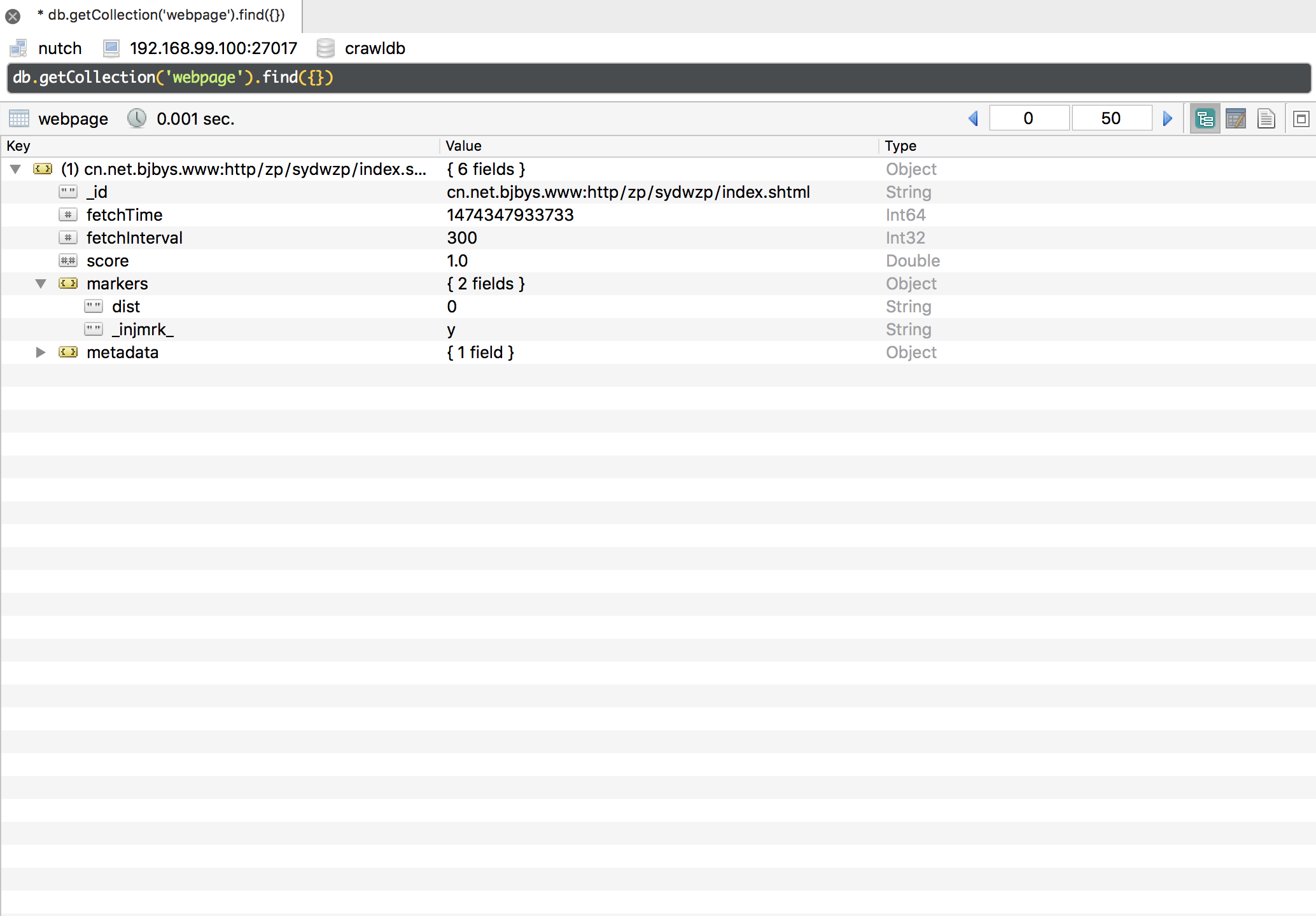
Generate
从抓取数据库中产生要抓取的页面放到抓取队列中去,产生batchJob。
|
|
该任务调用FetchSchedule来计算哪些url需要爬取。下面是官网wiki中关于任务的描述
The generate command looks up in the crawl db for all the urls due for fetch and regroup them in a segment. An url is due for fetch if it is either a new url or if it is time to re-crawl it.
包括Inject的Url以及fetchInterval时间已到的数据。
参数
- crawlId为必须的参数,为空的情况下使用
'' - 可以指定batchId,也可以让其生成随机值,batchId用于后续的任务选择
执行结果
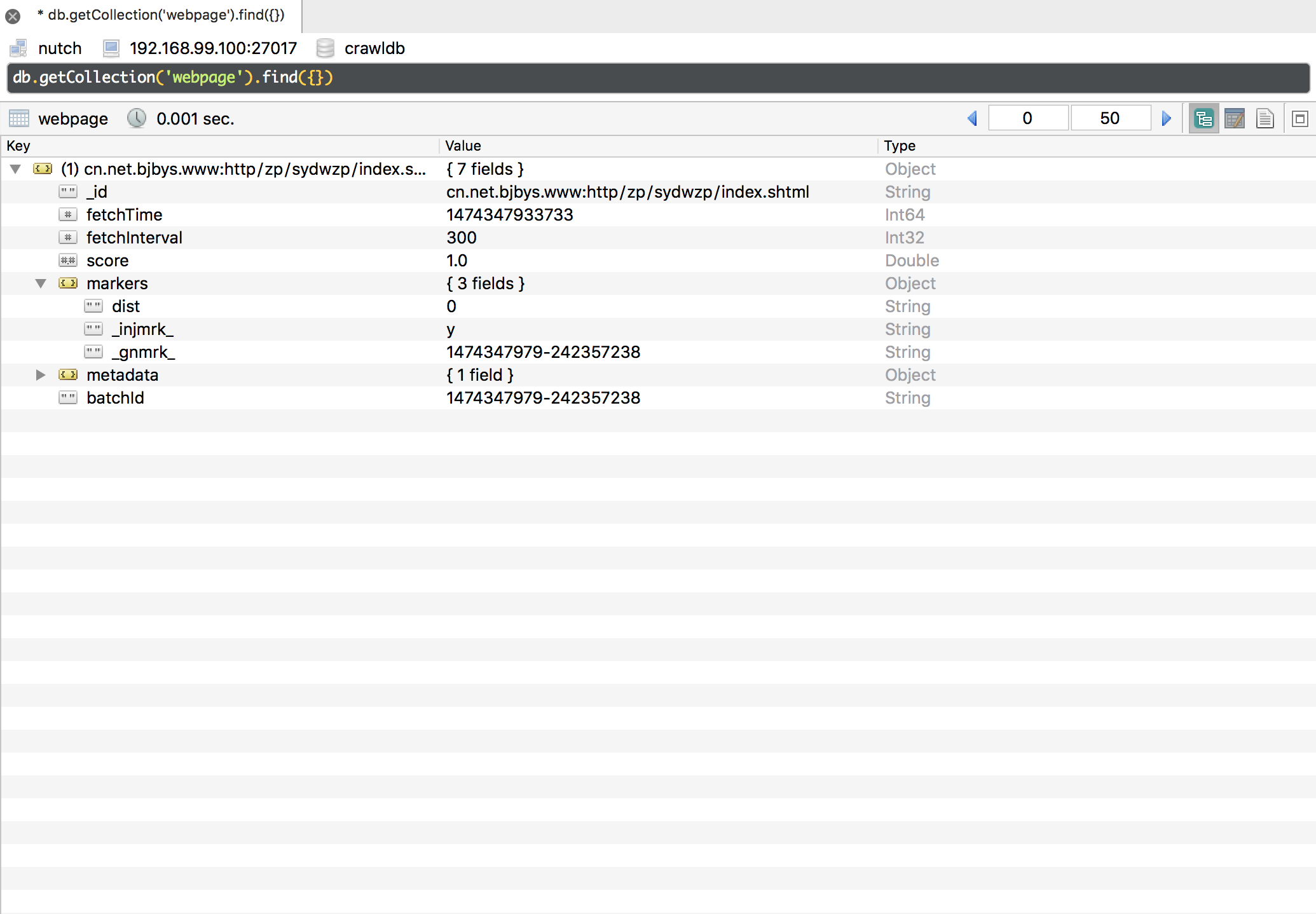
Fetch
对抓取队列中的网页进行抓取,在reducer中使用了生产/消费者模型
|
|
参数
- batchId为必须的参数,上一步指定或生成的batchId,或者
-all - crawlId为必须的参数,不加参数的情况下使用默认空值
该步骤处理的webpage的条件是gnmrk和batchId一致。
执行结果
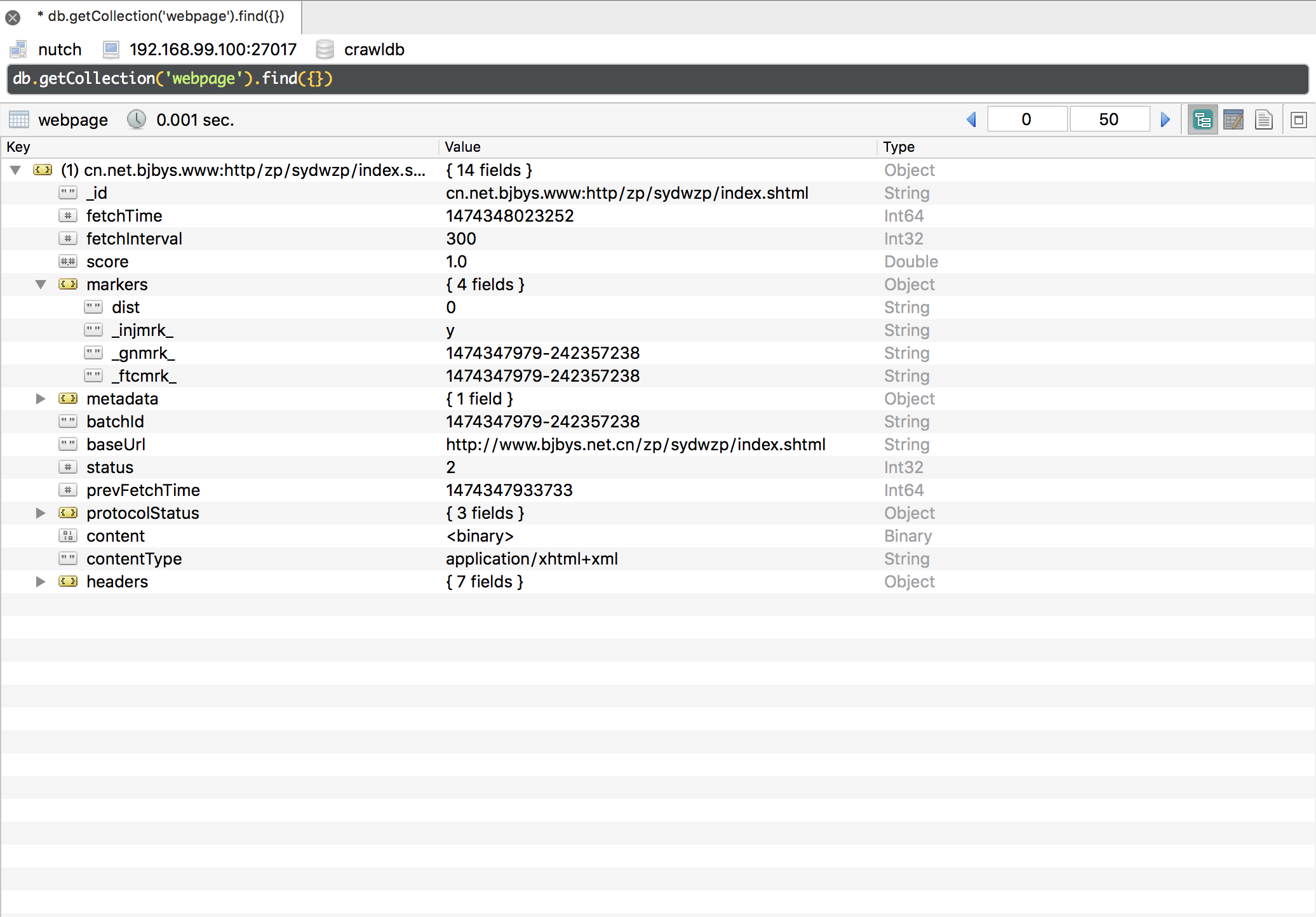
Parse
对抓取完成的网页进行解析,产生一些新的链接与网页内容的解析结果
|
|
参数
- batchId为必须的参数,上一步指定或生成的batchId,或者
-all - crawlId为必须的参数,不加参数的情况下使用默认空值
该步骤处理的webpage的条件是ftcmrk和batchId一致。
执行结果
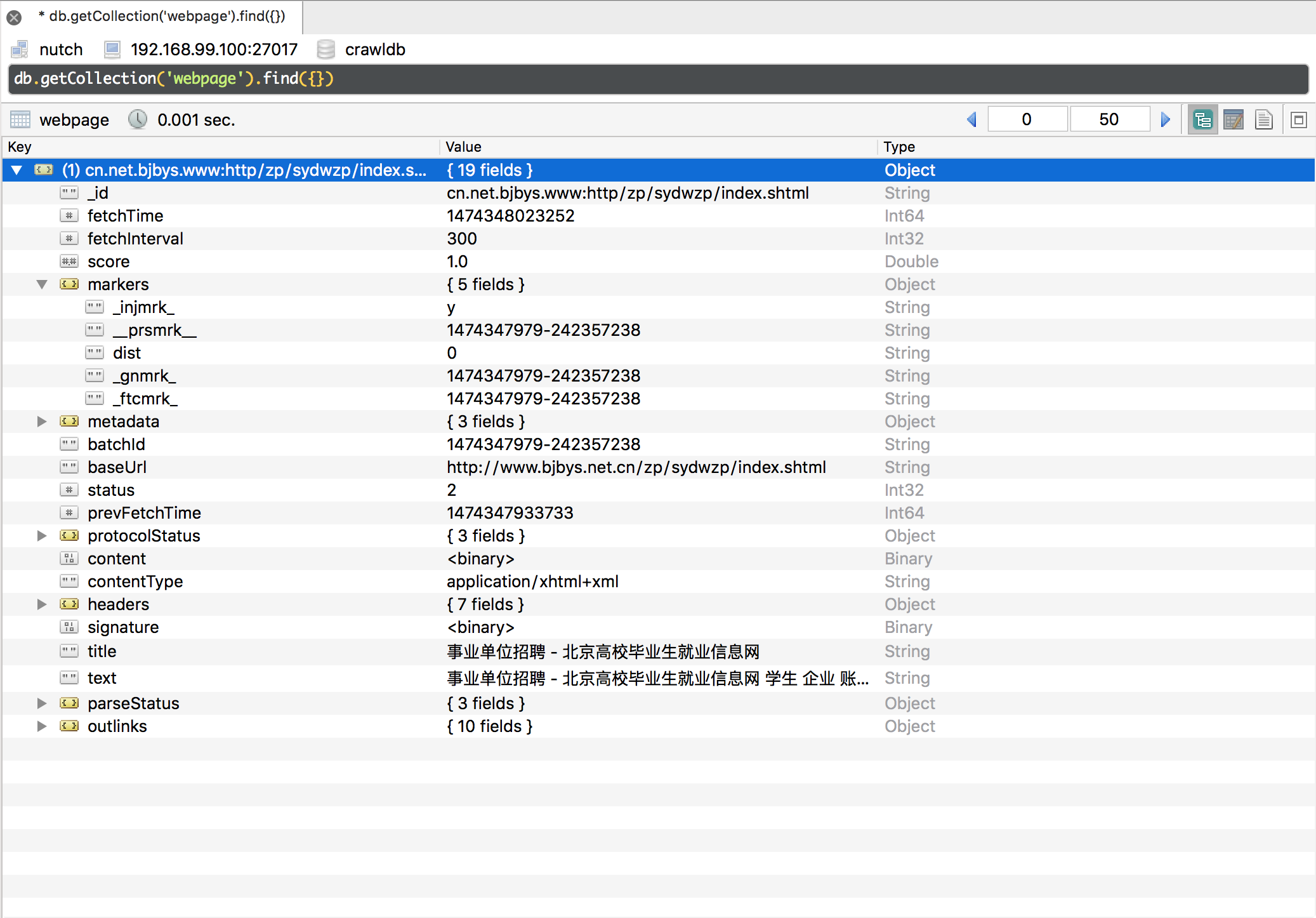
Updatedb
把新产生的链接更新到抓取数据库中去
|
|
参数
- batchId为必须的参数,上一步指定或生成的batchId,或者
-all - crawlId为必须的参数,不加参数的情况下使用默认空值
该步骤处理的webpage的条件是gnmrk和batchId一致。
执行结果
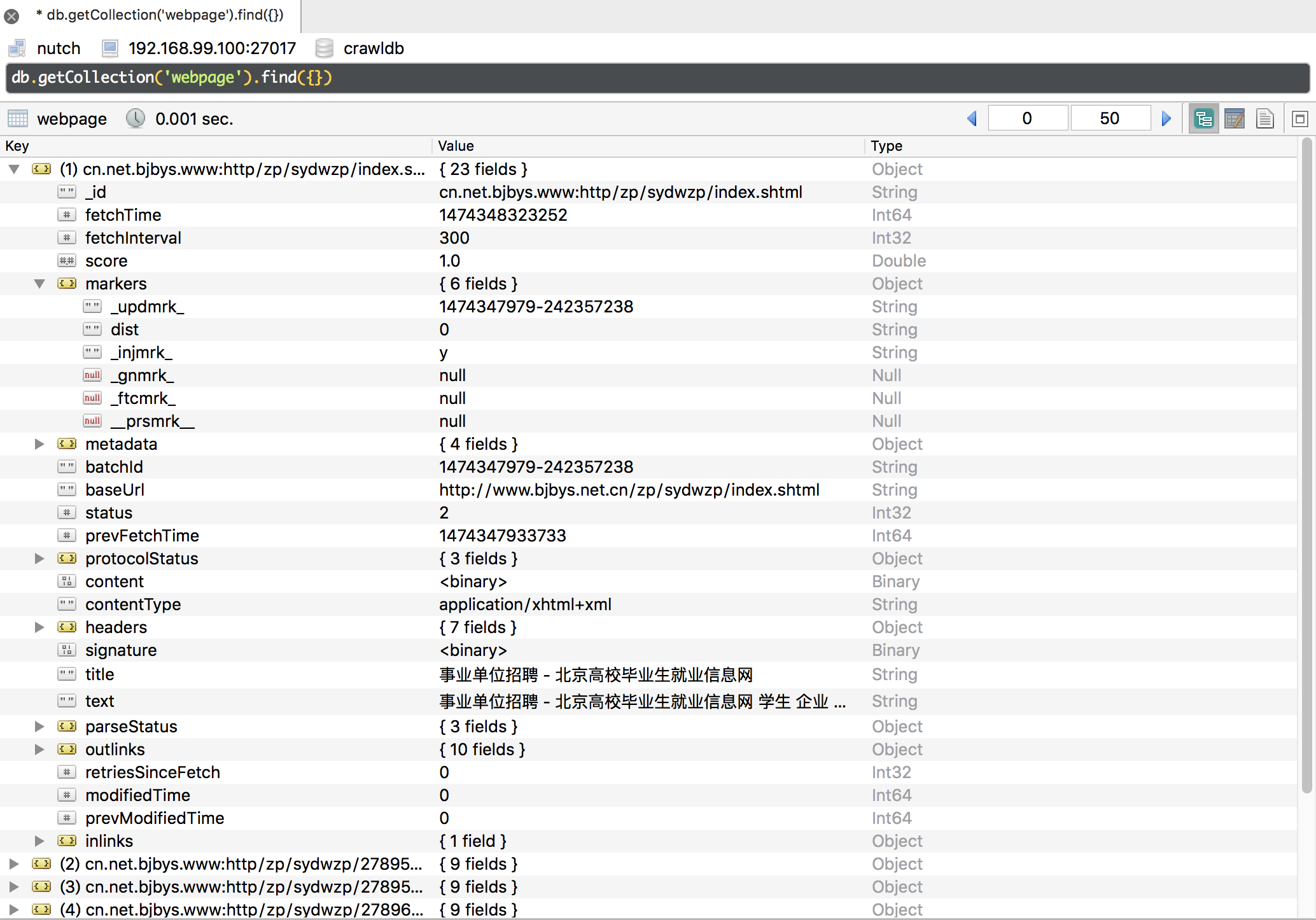
Crawl脚本
Crawl脚本的执行的流程是先执行Inject,然后循环执行Genrate、Fetch、Parse、Updatedb。 循环的次数依赖于numberOfRounds参数,同时先是爬取的深度。
关于FetchTime的更新
Webpage中的FetchTime是Generator的重要参考值,字段更新规则如下
- Inject和Fetch会更新fetchTime成当前时间
- Updatedb会更新fetchTime为当前时间+fetchInternal
开发
IDEA中使用
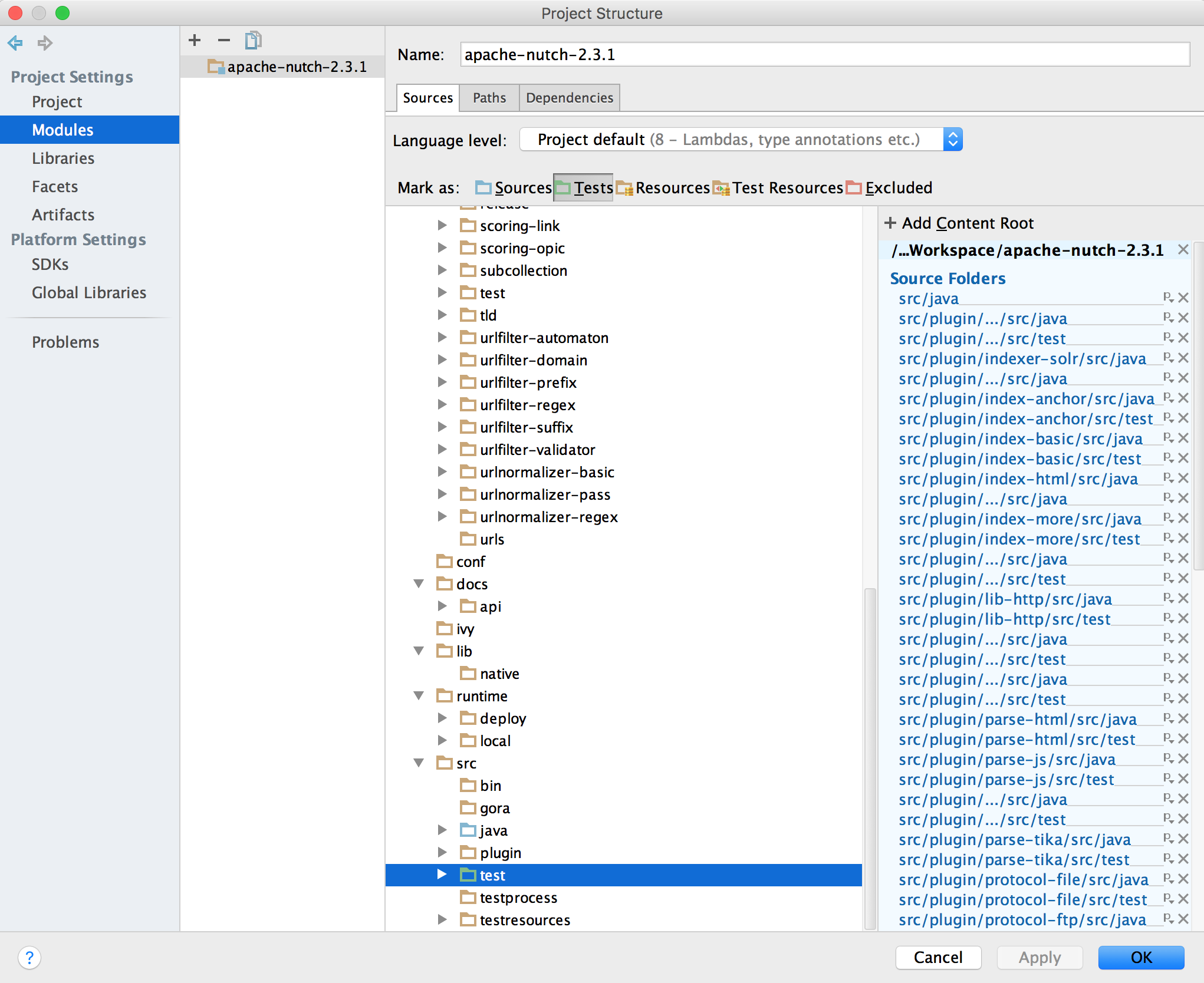
导入
先转换成eclipse工程后导入即可
|
|
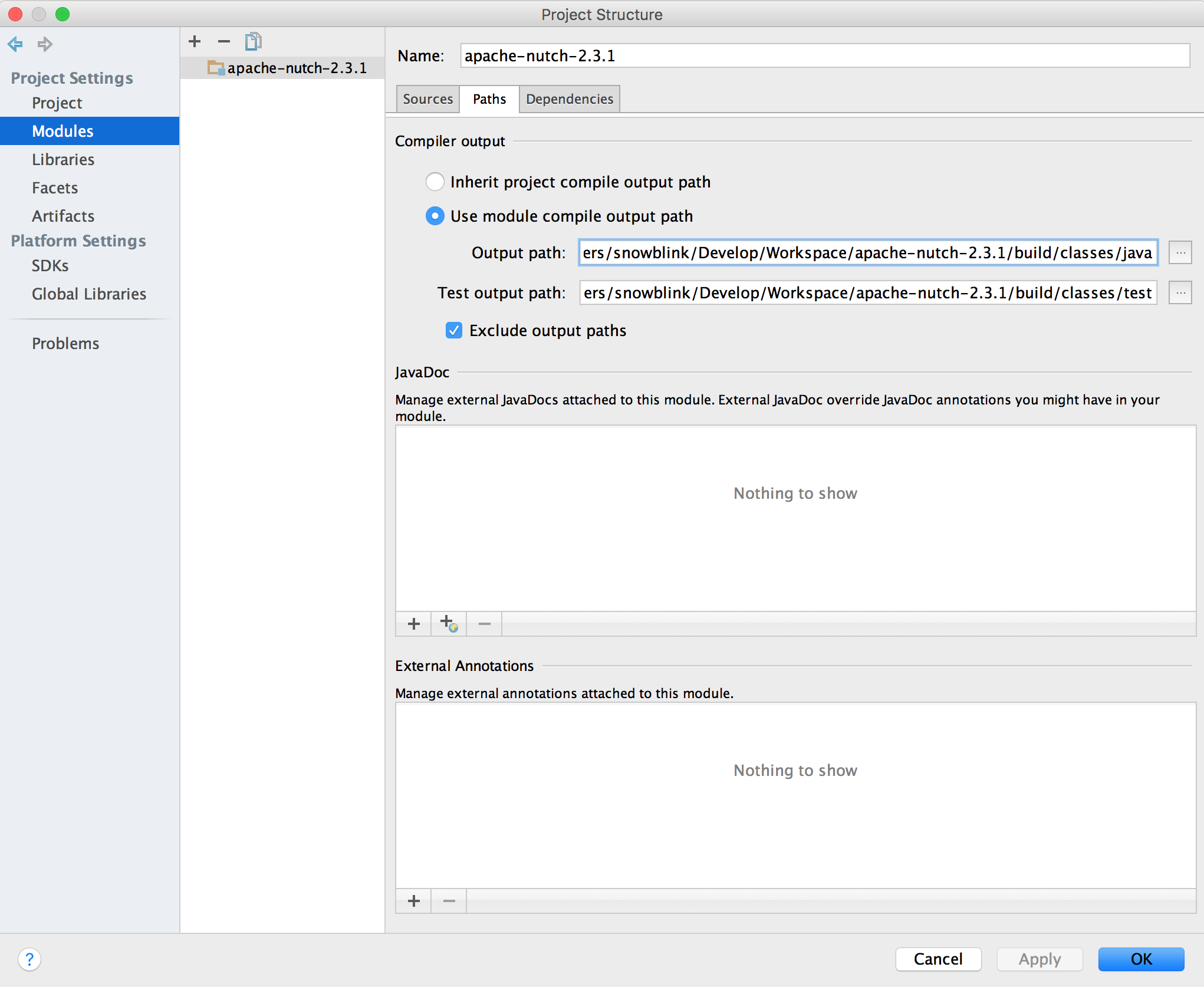
Test目录标记成test,并且把src和test输出到不同的目录,避免测试代码干扰正常的执行。
运行
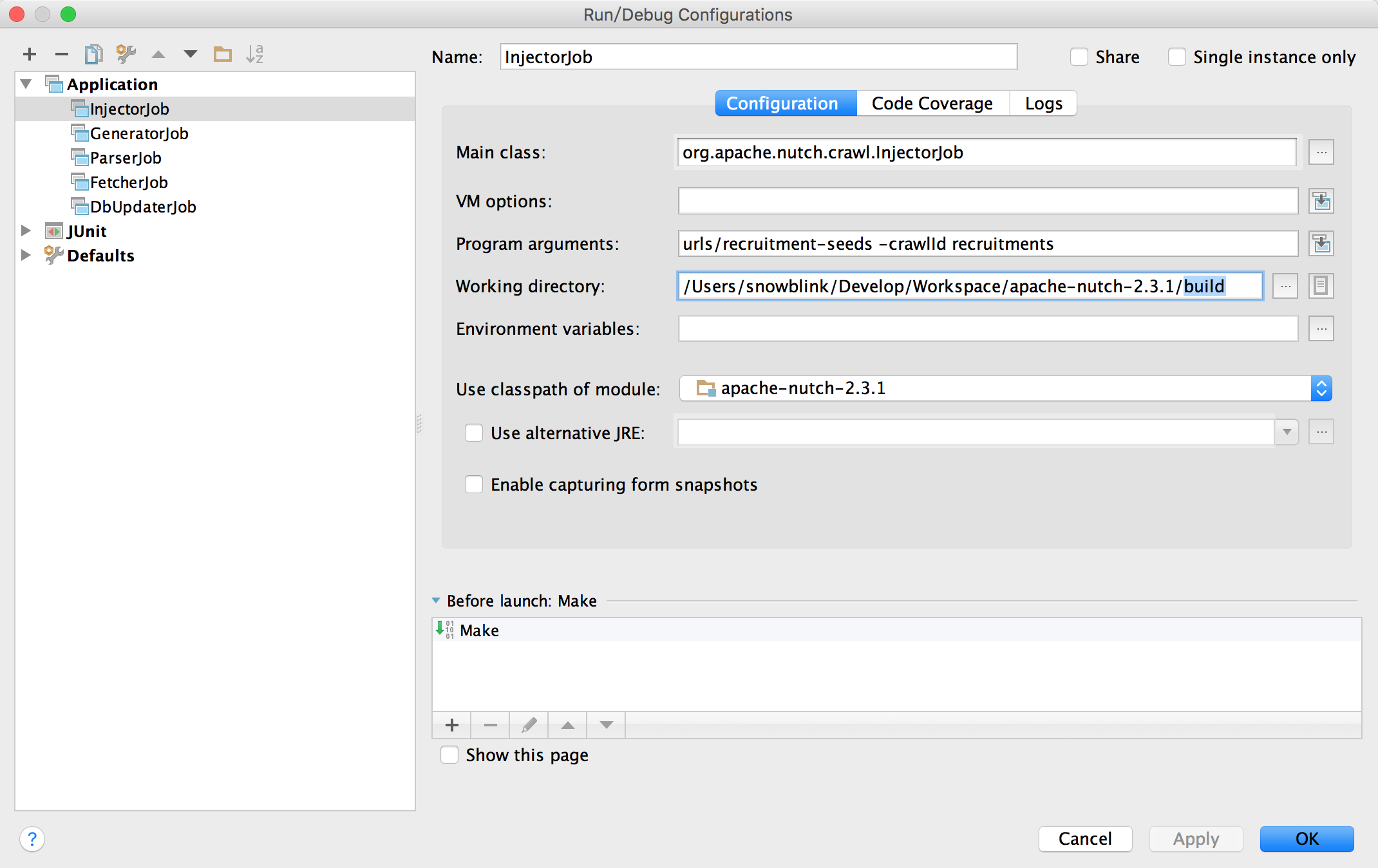
通过分别运行InjectorJob,GeneratorJob,FetcherJob,ParseJob,DBUpdaterJob类的Main方法可即可执行各个爬取步骤。
NOTE: Working Directory要修改到build目录,才能正确获取到正确的运行环境。
插件更新
插件源码的修改需要更新build目录中的class文件及配置。
|
|
